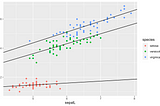
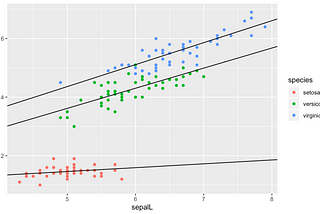
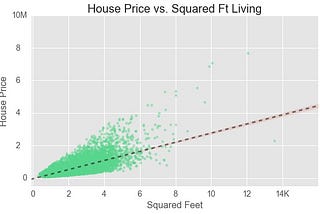
Adrià LuzinTowards Data ScienceOn the role of dummy variables and interactions in linear regressionUnderstanding this will help you be more in control when fitting linear models7 min read·Nov 3, 2020--2--2
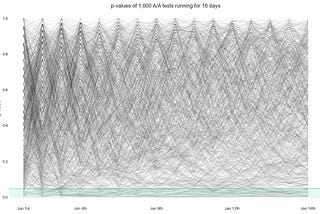
Adrià LuzinTowards Data ScienceOn A/A tests, p-values, significance, and the uniform distributionSimulating 1,000 A/A tests to understand how p-values are distributed4 min read·Oct 14, 2020--1--1
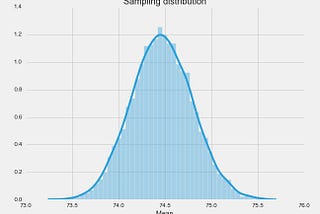
Adrià LuzThe bootstrap — or why you should care about uncertaintyby Adrià Luz5 min read·Sep 10, 2018----
Adrià LuzVisualising football players in two dimensions with PCAby Adrià Luz6 min read·Dec 20, 2017----
Adrià LuzinTowards Data ScienceWhy you should be plotting learning curves in your next machine learning projectSpoiler: they will help you understand whether your model suffers from high variance or high bias — and I’ll explain what you can do about…5 min read·Nov 26, 2017----